
Oracle Databaseを運用していて、表領域が足りなくなってくる。
使用率のしきい値を超えてアラートが出ている。
表領域の空きが少なくなっているが、追加するためのデータファイルが無い、または残り少ない。
そんなDBを運用している場合、既存の表や索引で断片化してるのを解消することで、新たにデータファイルを追加しなくても、表領域の空き領域を増やすことができます。
表領域の容量が足りなくなったら、盲目的にデータファイルを追加するのではなく、断片化を解消することで、効率よく表領域を利用し、更には表や索引のアクセススピードを上げることも可能です。
Oracle Databaseにおいて、表や索引を作り、その後の運用でInsertやUpdate、Deleteの更新処理によって、段々と表や索引の使用領域が断片化していきます。
断片化のデメリットとして、無駄に領域を使用したり、Selectでの参照において読み込むブロック数が増えるといった性能への影響もあります。
ですので、定期的に断片化解消の運用を行うことが、未然に性能劣化を防ぐ手当になります。
表の断片化
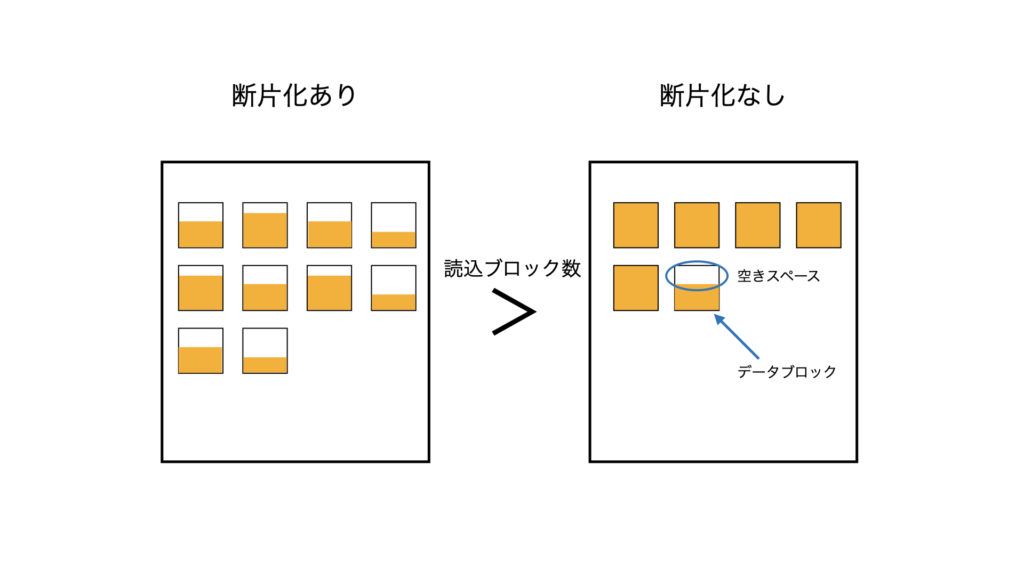
表の断片化はデータの更新・削除によって表内部で空き領域が分散している状態になります。
索引と違い、行を格納するブロックが値によって影響されないため、表の空きブロックは再利用されるが、読み込みブロック量は多くなります。
特にFull Scanは表全体のブロックを読み込むため、断片化による処理影響を最も強く受けます。
表断片化の確認方法
表断片化は、セグメントの管理方法と、セグメント内の空きブロックの状況により確認します。
- セグメントの管理方法の確認
次のSQLを実行し、表を格納する表領域のセグメントの管理方法を確認
SQL>select SEGMENT_SPACE_MANAGEMENT
from DBA_TABLESPACES
where TABLESPACE_NAME = '<表領域名>';- 管理方法の結果から、各方法で空きブロク状況を確認する
- 管理方法がAUTOの場合
自動セグメント領域管理(ASSM)を使用しているため、
DBMS_SPACE.SPACE_USAGEプロシージャを使用する - 管理方法がMANUALの場合
フリーリスト管理を使用しているため、
DBMS_SPACE.UNUSED_SPACEプロシージャを使用する
- 管理方法がAUTOの場合
【ASSMセグメントの場合の表断片化の確認方法】
SQL>set serveroutput on
SQL>declare
v_unformatted_blk number; v_unformatted_b number;
v_fs1_blk number; v_fs1_b number; v_fs2_blk number; v_fs2_b number;
v_fs3_blk number; v_fs3_b number; v_fs4_blk number; v_fs4_b number;
v_full_blk number; v_full_b number; v_frag_rate number;
begin
dbms_space.space_usage(
segment_owner=>’SH’, segment_name=>’PRODUCTS’, segment_type=>’TABLE’,
unformatted_blocks=>v_unformatted_blk, unformatted_bytes=>v_unformatted_b,
fs1_blocks=>v_fs1_blk, fs1_bytes=>v_fs1_b, fs2_blocks=>v_fs2_blk, fs2_bytes=>v_fs2_b,
fs3_blocks=>v_fs3_blk, fs3_bytes=>v_fs3_b, fs4_blocks=>v_fs4_blk, fs4_bytes=>v_fs4_b,
full_blocks=>v_full_blk, full_bytes=>v_full_b
);
v_frag_rate := (v_fs1_blk*1+v_fs2_blk*0.75+v_fs3_blk*0.50+v_fs4_blk*0.25)/
(v_fs1_blk+v_fs2_blk+v_fs3_blk+v_fs4_blk+v_full_blk);
dbms_output.put_line(‘Unformatted Blocks = ‘ || v_unformatted_blk);
dbms_output.put_line(‘0 - 25% free blocks = ‘ || v_fs1_blk);
dbms_output.put_line('25 - 50% free blocks = ' || v_fs2_blk);
dbms_output.put_line('50 - 75% free blocks = ' || v_fs3_blk);
dbms_output.put_line('75 - 100% free blocks = ' || v_fs4_blk);
dbms_output.put_line('Full Blocks = ' || v_full_blk );
dbms_output.put_line('============================');
dbms_output.put_line('Fragmentation Rate = ' || round(v_frag_rate, 3));
end;
/上記SQLの結果で、
・「XX-YY free blocks」:空き領域がXX%〜YY%のブロック数
・「Full Blocks」:セグメントがいっぱいになった(PCTFREEに達した)ブロック数
を表しています。
断片化率の考え方は以下のとおり
断片化率 = (HWM下にあるフォーマット済のブロックの空き領域合計) / (HWM下にあるフォーマット済のブロックサイズ合計)
断片化の解消対象の目安としては、
・セグメントサイズ >= 1GB かつ 断片化率 >=40%
といったところでしょうか。もちろん運用しているシステムによってサイズのしきい値は変更すべきですが。
【フリーリスト管理セグメントの表断片化確認方法】
SQL>set serveroutput on
SQL>declare
v_total_blk number; v_total_b number; v_unused_blk number; v_unused_b number;
v_lu_ext_file_id number; v_lu_ext_blk_id number; v_lu_blk number; v_frag_rate number;
begin
dbms_space.unused_space(
segment_owner=>’SH’, segment_name=>’PRODUCTS’, segment_type=>’TABLE’,
total_blocks=>v_total_blk, total_bytes=>v_total_b, unused_blocks=>v_unused_blk,
unused_bytes=>v_unused_b, last_used_extent_file_id=>v_lu_ext_file_id,
last_used_extent_block_id=>v_lu_ext_blk_id, last_used_block=>v_lu_blk
);
v_frag_rate := v_unused_blk / v_total_blk;
dbms_output.put_line('TOTAL BLOCKS = ' || v_total_blk);
dbms_output.put_line('UNUSED BLOCKS = ' || v_unused_blk);
dbms_output.put_line('===============================');
dbms_output.put_line('Fragmentation Rate = ' || round(v_frag_rate, 3));
end;
/上記SQLの結果で、
・「TOTAL_BLOCKS」:HWM下の全ブロック数
・「UNUSED_BLOCKS」:未使用ブブロック数
断片化率と解消対象の考え方は上記ASSMセグメントの考え方と同じ。
表断片化の解消方法
以下のいずれかを実施する
- SHRINK SPACEを実行し、表を圧縮
- Moveを実行し、表を再構築
- Expdp/Impdpを実行し、再作成
上記の中でオススメするとしたら、2.Moveでしょうか。
同じ表領域の中で再作成するのでキレイに断片化が解消されます。
1.SHRINKは元表内での圧縮なので、若干、断片化が残るイメージ。
3.Expdp/Impdpは一旦、ファイルを吐き出して、入れ直すので、2.Moveよりは若干手間なイメージです。
【表断片化の解消方法〜SHRINK SPACE〜】
断片化解消のために提供されているOracleのコマンド。
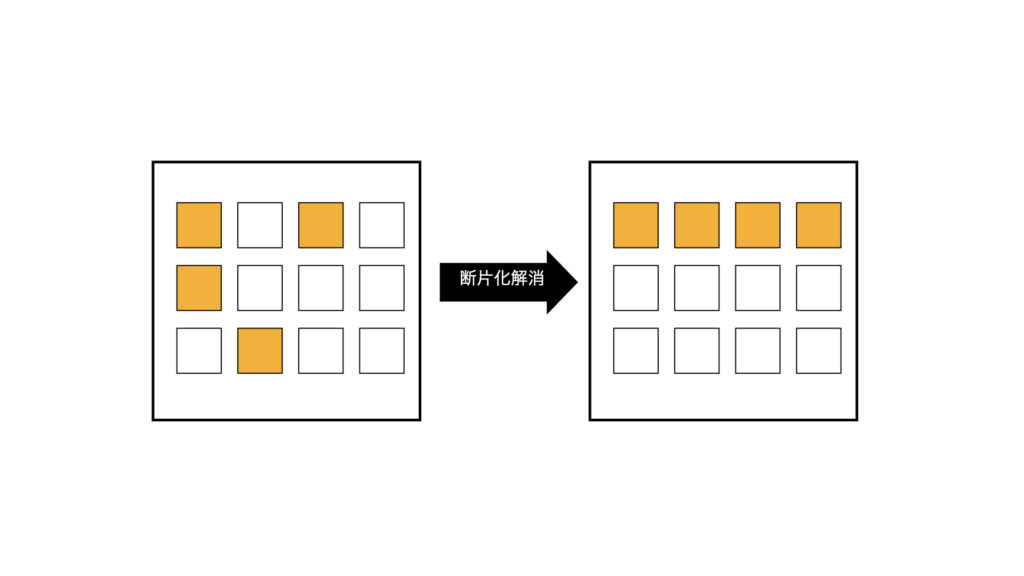
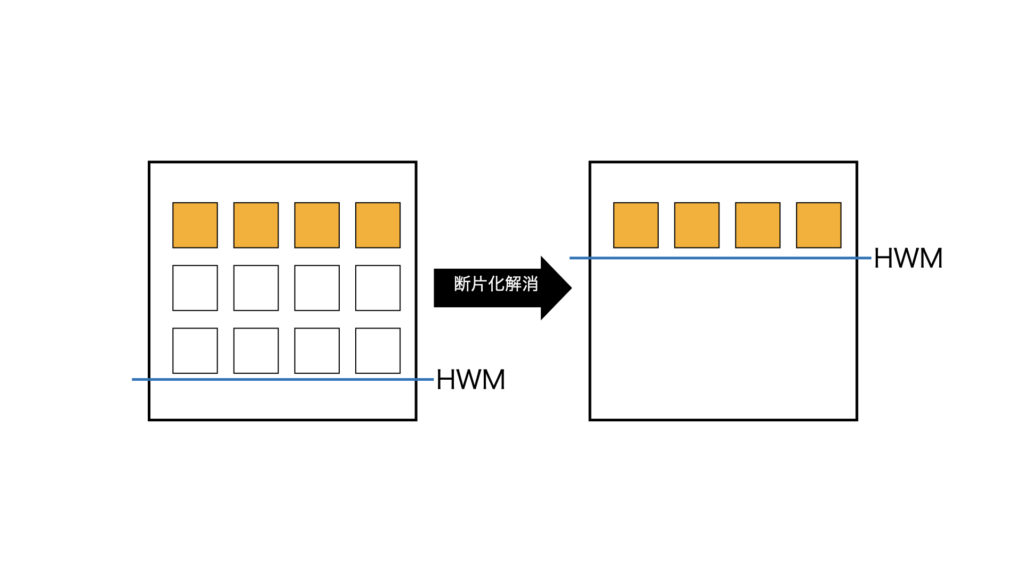
COMPACTIONとSHRINKの2ステップで構成されている。
COMPACTIONで表データの断片化を解消し、SHRINKで未使用領域を開放する。
SQL>ALTER TABLE テーブル名 ENABLE ROW MOVEMENT; ※1
SQL>ALTER TABLE テーブル名 SHRINK SPACE;※1 あらかじめ表に対して行移動ができるようにしておく必要があります。
1)COMPACTIONのイメージ
2)SHRINKのイメージ
【表断片化の解消方法〜MOVE〜】
Oracle内部で表の再構築(コピー)することで断片化を解消する。
Move先の表領域に表のコピーを作成し、コピーが完了したら既存の表は削除される。索引がある場合はMove後に再構築が必須となる。
SQL>ALTER TABLE テーブル名 MOVE;1)コピーのイメージ
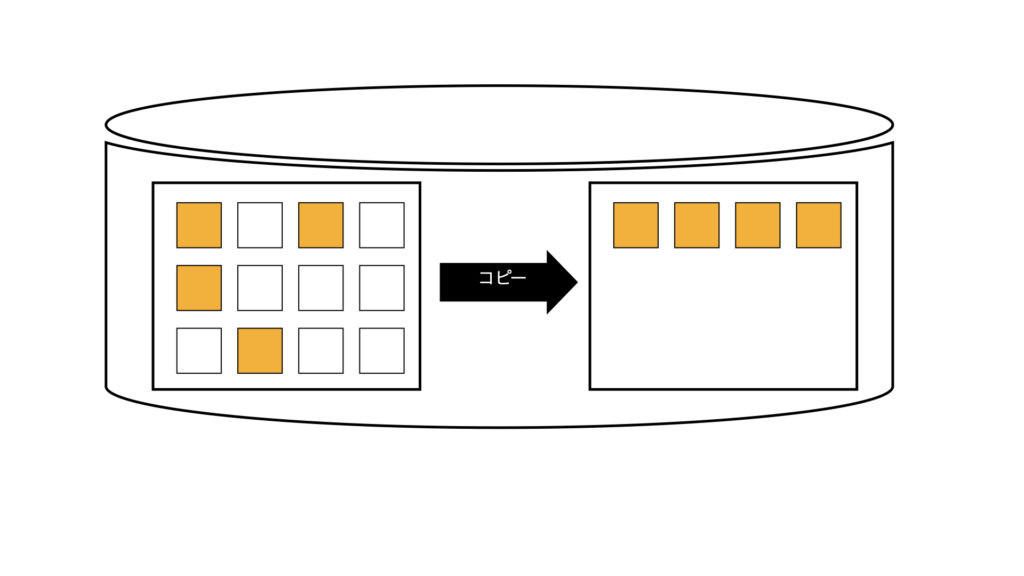
(2)コピー後の元表の削除イメージ

【表断片化の解消方法〜Expdp/Impdp〜】
Expdp/Impdpによって表、索引の再作成することで断片化を解消する。
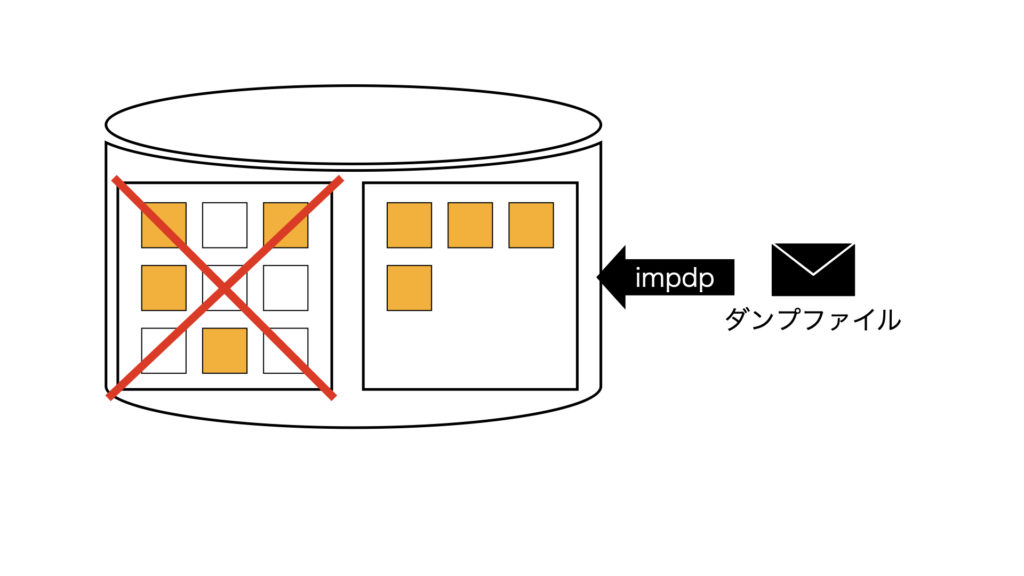
ExpdpでOS上のファイルにデータを出力し、オブジェクトの削除後にImpdpする。
1)ダンプファイルにexpdp
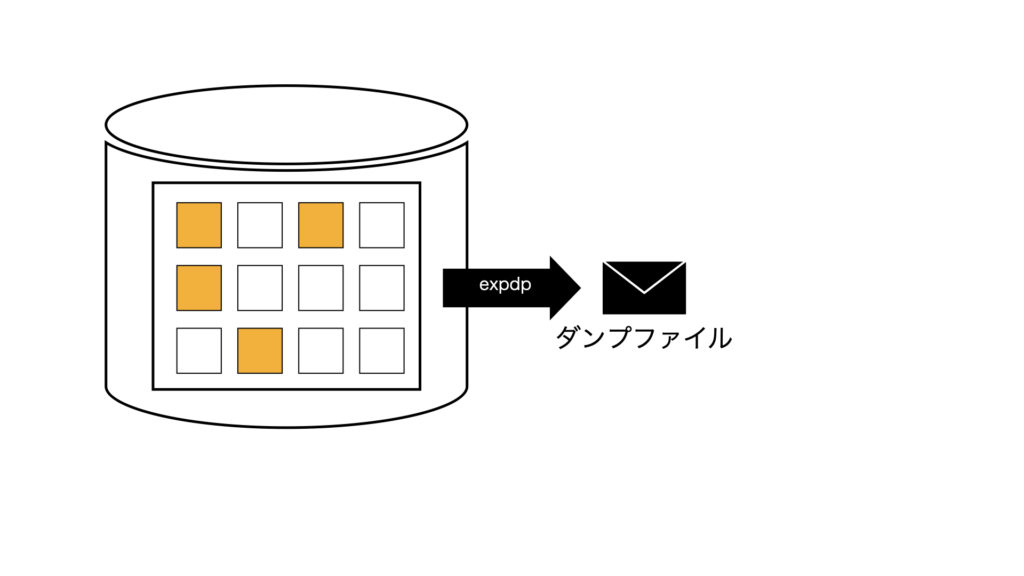
(2)元のオブジェクトは削除後、ダンプファイルからimpdp
各解消方法のメリット/デメリット
| 項目 | SHRINK | MOVE | Expdp/Impdp | |
|---|---|---|---|---|
| 断片化 解消効果 | 行移行の解消 | △格納データに依存 | ○ | ○ |
| HWMが下がる | △データ分布に依存 | ○ | ○ | |
| 実行時の影響 | 再編成中の問合せ | ○可 | △可またはORA-8103エラー発生 | ×エクスポート時のみ可 |
| 再編成中のDML | ○可(COMPACTIONの行ロック、SHRINK中の一時的な表の排他ロックあり) | △12.2以降のみ可 | ×不可 | |
| 再編成中の追加領域 | ○不要 | ×必要(実データ分以上の空き容量が必要) | △不要(ただしExpdpのためのディスクの空きが必要) | |
| 追加作業 | バックアップ | ×手動 | ×手動 | ○自動(ダンプファイルが残る) |
| 索引再編成 | ○不要 | ×手動 | ○自動 | |
| その他 | DB内の実装 | ○SQL(DBのJOB) | ○SQL(DBのJOB) | ×OSコマンド |
| 他の属性変更 | ×単独 | ○PCTFREEなども同時に変更可 | ×単独 | |
| パーティション表 | ○1コマンド | ×パーティション/サブパーティション毎に実行 | ○1コマンド | |
| バージョン、ライセンス情報 | - | 10g以降使用可能 ただし、PSR11.2.0.2より前のバージョンでは不具合あり | 8i以降使用可能 再構成中のDMLは12.2以降 | 10g以降使用可能 |
索引断片化
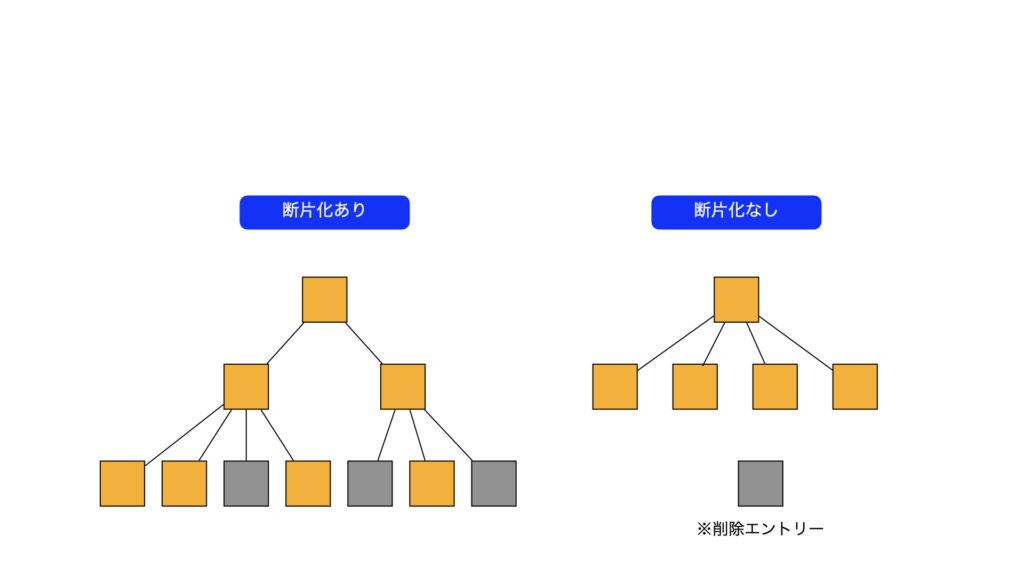
索引データの追加・削除によって、削除エントリーが増加し、領域が開放されずに残った状態です。
影響としては、読み込みブロック数が多くなる。索引は表と異なり、行を格納するブロックが値の範囲に影響されるため、先雨女後の空き領域が再利用されにくい傾向がある。
断片化が進行してブロック数が増加すると、不要にBツリーが高くなり、索引アクセス全体の性能に影響する。
削除エントリーの割合が増えるとRange Scanの性能に影響する。
索引断片化の確認方法
断片化の確認手順は以下のとおり。
- 索引を分析 ※排他テーブルロックが発生し、対象の表への更新が待たされる。
SQL>ANALYZE INDEX <索引名> VALIDATE STRUCTURE;- INDEX_STATSで確認
SQL>SELECT name, height, lf_rows, del_lf_rows FROM index_stats;索引再作成の目安としては、
・階層の高さ:4階層以上(HEIGHT >=4)かつ
・削除エントリーの割合:20〜30%を超える(DEL_LF_ROWS / LF_ROWS)
が大まかな目安になるかと。
索引断片化の解消方法
索引断片化の解消方法としては、以下を実施する。
- REBUILD(ONLINE)を実行し、索引を再編成
- DROP & CREATEを実行し、索引を再作成
- SHRINK SPACEを実行し、索引を圧縮
【索引断片化の解消方法〜REBUILD〜】
索引の再編成を実行する。ONLINEの指定有無で動作が変わる。
SQL>ALTER INDEX <索引名> REBUILD;
SQL>ALTER INDEX <索引名> REBUILD ONLINE;■内部動作のイメージ(ONLINEなし)
1)現索引のリーフブロックを読み込み、新しい索引を作成
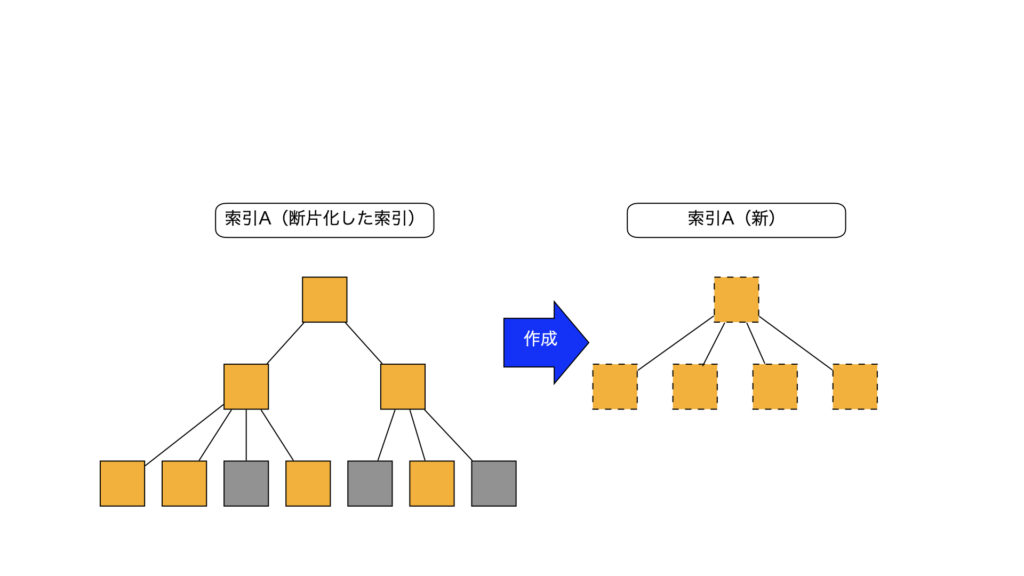
2)現索引を削除し、新しい索引をオンラインにする
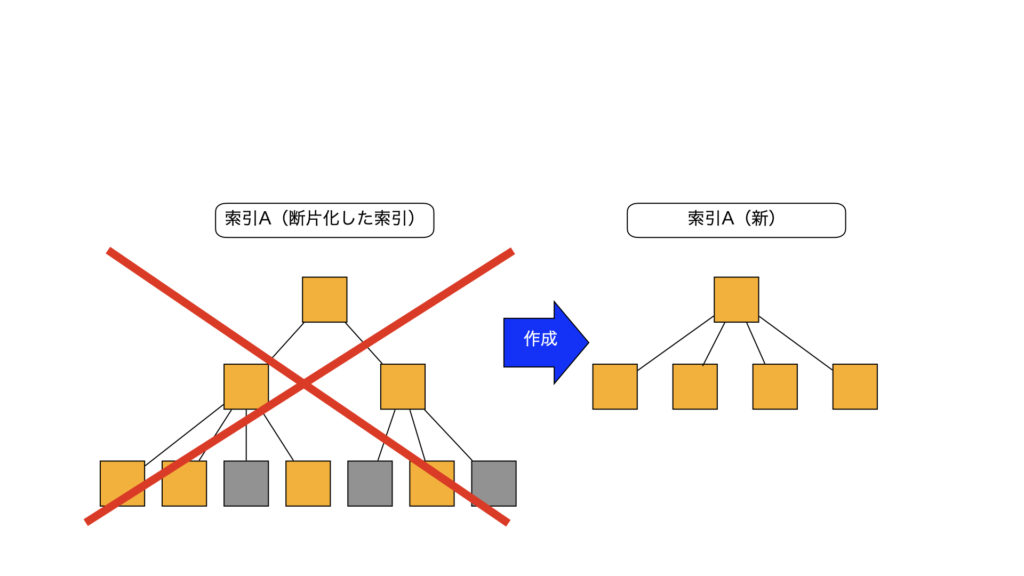
■内部動作のイメージ(ONLINEあり)
1)一時的に更新履歴を蓄積するジャーナル表を作成
2)表を全て読み込み、新しい索引を作成
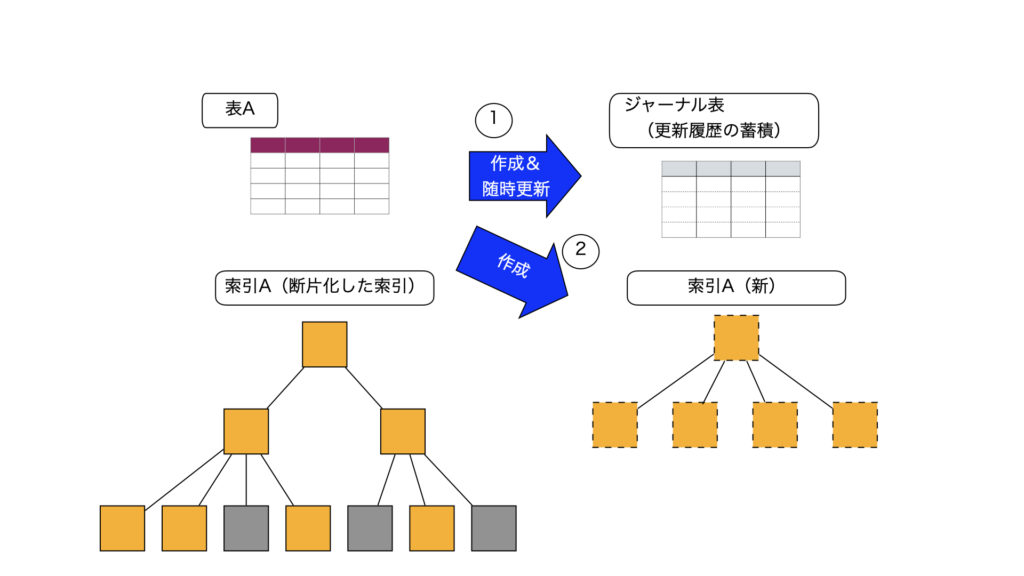
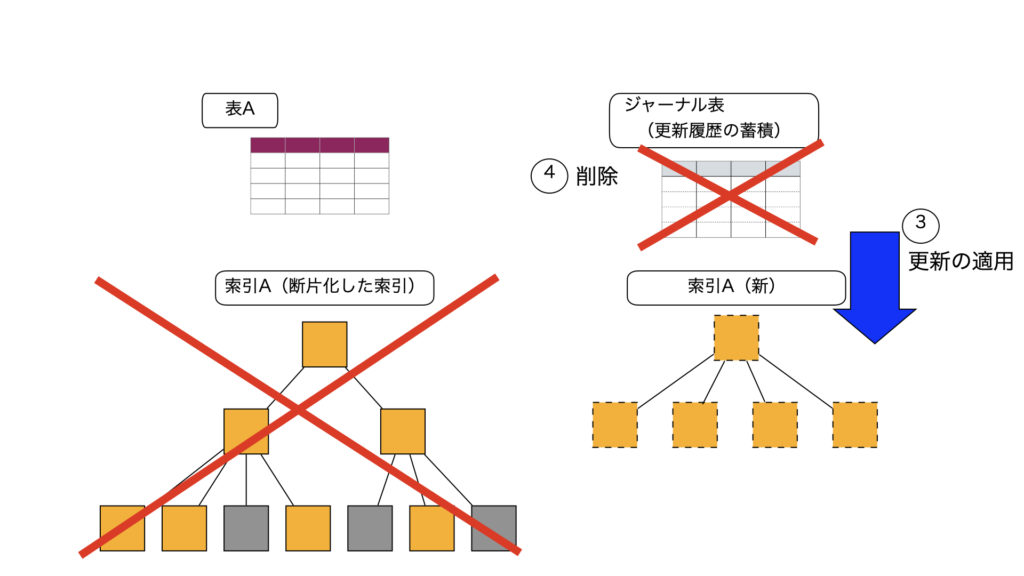
3)ジャーナル表に記録されている更新履歴を新しい索引に適用
4)ジャーナル表、現索引を削除し、新しい索引をオンラインにする
【索引断片化の解消方法〜DROP & CREATE〜】
索引を削除し、再作成することで断片化を解消可能。
索引作成時に表を読み込んで作成するため、REBUILD(ONLINEなし)と比べ、断片化解消に時間がかかる。
1)索引を削除
SQL>DROP INDEX <索引名>;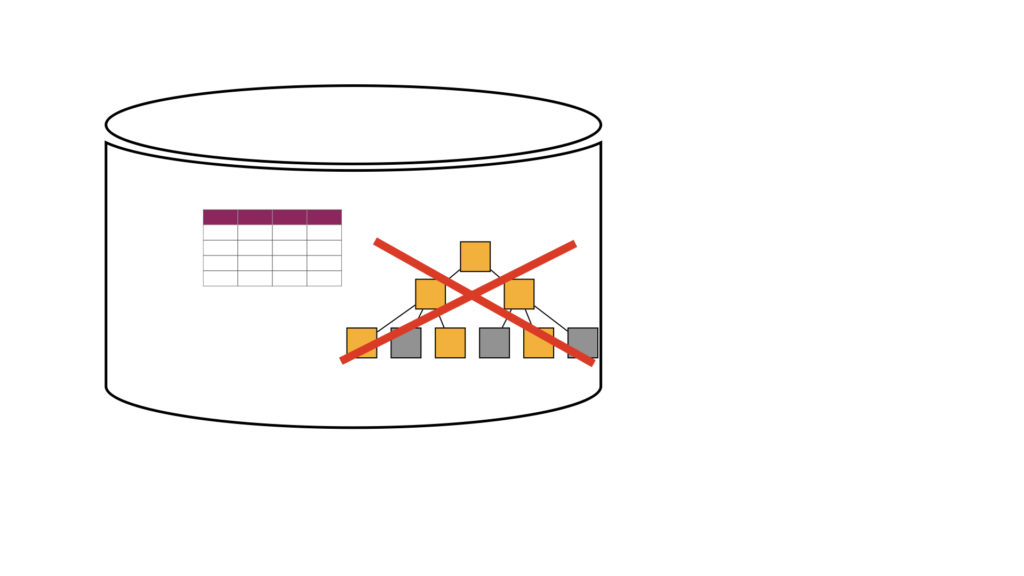
2)索引を再作成
SQL>CRETE INDEX <索引名> ON <テーブル名(列名)など;
【索引断片化の解消方法〜SHRINK SPACE〜】
同じブランチ内で、空き領域が50%以上存在し、(論理的に)隣り合った2つのリーブ・ブロックを結合し、未使用領域を開放する。
SQL>ALTER INDEX <索引名> SHRINK SPACE;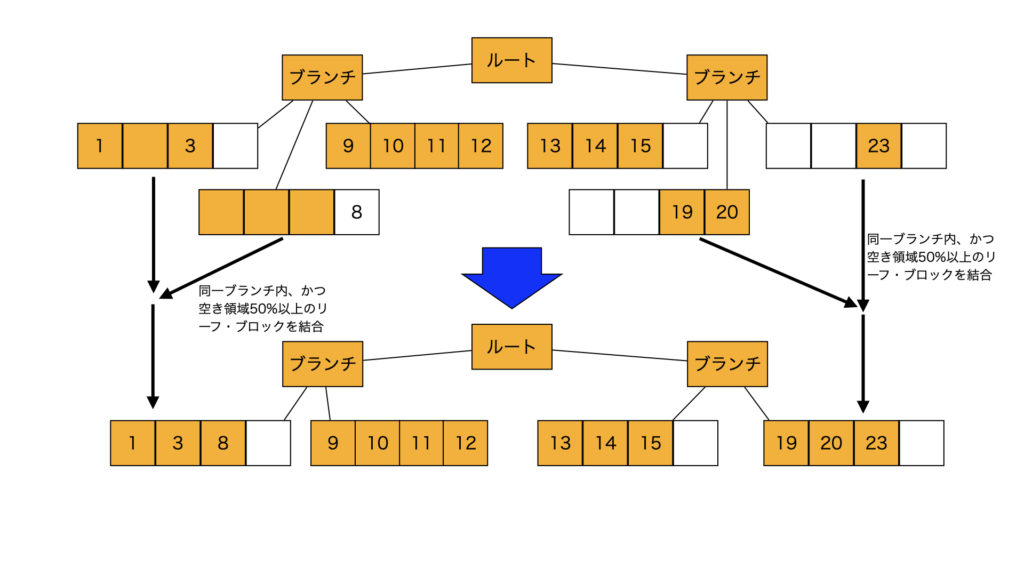
各解消方法のメリット/デメリット
| 項目 | REBUILD | REBUILD ONLINE | DROP&CREATE | SHRINK SPACE | SHRINK SPACE COMPACT | |
|---|---|---|---|---|---|---|
| 断片化の解消効果 | B-tree高さの圧縮 | ○可 | ○可 | ○可 | ✗不可 | ✗不可 |
| リーフ・ブロックの圧縮 | ○可 | ○可 | ○可 | ○可 | ○可 | |
| 未使用領域の開放 | ○可 | ○可 | ○可 | ○可 | ✗不可 | |
| 実行時の影響 | 再編成中の問合せ | ○可 | ○可 | △可(索引を削除しているため性能低下の可能性あり) | ○可 | ○可 |
| 再編成中のDML | ✗不可 | △可(一時的な表の共有ロックあり(〜10g)) | ✗不可 | △可(移動中の行ロック有、一時的な表の排他ロック有) | △可(移動中の行ロック有) | |
| 再編成中の追加領域 | ✗必要(オリジナル + 新規分の領域) | ✗必要(オリジナル + ジャーナル表) | ○不要 | ○不要 | ○不要 | |
| オンライン/オフライン | - | ✗オフライン | ○オンライン | ✗オフライン | ○オンライン | ○オンライン |
| バージョン、ライセンス情報 | - | ・8i以降使用可能 | ・8i以降使用可能 ・Enterprise Editionのみ | - | ・10g以降のみ (ASSM表領域必須) | ・8i以降使用可能 |
REBUILD(ONLINEなし)実行中は索引が使用できないため、システムによっては業務停止やメンテナンス時間に実施するか、他の手段を利用することを検討。
索引REBUILDのチューニング
索引を作成、再編成する際にはソート処理が発生するが、自動PGAの場合には1セッションあたりのメモリソート領域が、PGA_AGGREGATE_TARGETとの比率に依存して制限されている。
そのため、ただREBUILDするだけでは、この制限により時間が掛かる場合がある。
索引再編成の高速化については以下の2点が考えられる。
- メモリソート領域の拡大
ALTER INDEX … REBUILD / ALTER INDEX … REBUILD ONLINE で索引の再編成を行う際に、下記SQLを実行してセッション単位でメモリソート領域を拡大することでディスクソートを避けて、高速化に再編成できる。
SQL>ALTER SESSION SET WORKAREA_SIZE_POLICY = MANUAL;
SQL>ALTER SESSION SET SORT_AREA_SIZE = <任意サイズ>;(最大2GB )
SQL>ALTER INDEX <索引名> REBUILD;- 再編成のパラレル化
パラレル化を行うことで並列読み込み、並列作成のメリットがあるだけでなく、メモリソート領域が増加するというメリットもある。
1.でセッションあたりのメモリソート領域を拡大しておくと、パラレル化した場合には各パラレル・スレーブ・プロセス(PQ)毎に設定が適用されるため、最大サイズがより大きなメモリソート領域を確保することが可能になる。 ◆セッションがPGAの最大2GBである環境でのシリアル/パラレル実行での動作イメージ
<シリアル実行>
SQL>ALTER INDEX <索引名> REBUILD;<パラレル実行>
SQL>ALTER INDEX <索引名> REBUILD PARALLEL 4;※注意としてPARALLEL REBUILD実行後は指定したパラレル度が索引のデフォルトのDEGREEとしてセットされ、意図せず、パラレルクエリの実行計画に変わる可能性があるため、ALTER INDEX文により、索引のデフォルトDEGREEを元の設定に戻す必要がある。